Python代码规范¶
规范英文名:HiveNet Python Coding Standards
规范中文名:HiveNet Python代码规范
HiveNet标识名:hivenet_python_coding_standards
HiveNet版本:v1.1.0
参考文档:使用Sphinx为你的python模块自动生成文档 https://blog.csdn.net/preyta/article/details/73647937
参考文档:JSDoc中文文档 http://www.css88.com/doc/jsdoc/index.html
代码风格规范¶
本章定义的是Python代码的编写风格,旨在指导开发人员所编写的代码风格统一且保障较好的可读性(遵循PEP 8规范)。
分号¶
不要在行尾加分号, 也不要用分号将两条命令放在同一行 。
行长度¶
每行不超过80个字符,以下情况除外:
长的导入模块语句
注释里的URL
注意不要使用反斜杠连接行,Python会将圆括号,中括号和花括号中的行隐式的连接起来,你可以利用这个特点。如果需要,你可以在表达式外围增加一对额外的圆括号。
x = ('这是一个非常长非常长非常长非常长 '
'非常长非常长非常长非常长非常长非常长的字符串')
括号¶
宁缺毋滥的使用括号,除非是用于实现行连接, 否则不要在返回语句或条件语句中使用括号。不过在元组两边使用括号是可以的。
缩进¶
用4个空格来缩进代码,绝对不要用tab,也不要tab和空格混用。对于行连接的情况,你应该要么垂直对齐换行的元素,或者使用4空格的悬挂式缩进(这时第一行不应该有参数) 。
# 与起始变量对齐
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 字典中与起始值对齐
foo = {
long_dictionary_key: value1 +
value2,
...
}
# 4 个空格缩进,第一行不需要
foo = long_function_name(
var_one, var_two, var_three,
var_four)
# 字典中 4 个空格缩进
foo = {
long_dictionary_key:
long_dictionary_value,
...
}
空行¶
顶级定义之间空两行, 次级定义之间空一行。顶级定义指代码文件第1层的定义,包括类定义、函数定义、变量定义等,定义之间空两行;次级定义指在类内部或函数内部的方法、变量定义,定义之间空一行。函数或方法中, 某些地方要是你觉得合适, 就空一行。
注意:汇集在一起的变量定义无需空行,或可按块空一行。
空格¶
不要在逗号, 分号, 冒号前面加空格, 但应该在它们后面加(除了在行尾)。
按照标准的排版规范来使用标点两边的空格,但括号两边不要有空格。
在二元操作符两边都加上一个空格, 比如赋值(=), 比较(==, <, >, !=, <>, <=, >=, in, not in, is, is not), 布尔(and, or, not)。至于算术操作符两边的空格该如何使用, 需要你自己好好判断. 不过两侧务必要保持一致。
当’=’用于指示关键字参数或默认参数值时, 不要在其两侧使用空格。
规范: def complex(real, imag=0.0): return magic(r=real, i=imag)
不规范: def complex(real, imag = 0.0): return magic(r = real, i = imag)
不要用空格来垂直对齐多行间的标记, 因为这会成为维护的负担(适用于:, #, =等) 。
导入格式¶
每个导入应该独占一行。 ,
导入总应该放在文件顶部, 位于模块注释和文档字符串之后, 模块全局变量和常量之前. 导入应该按照从最通用到最不通用的顺序分组:
标准库导入第三方库导入应用程序指定导入
每种分组中, 应该根据每个模块的完整包路径按字典序排序, 忽略大小写。
字符串¶
规范:
x = a + b
x = '%s, %s!' % (imperative, expletive)
x = '{}, {}!'.format(imperative, expletive)
x = 'name: %s; score: %d' % (name, n)
x = 'name: {}; score: {}'.format(name, n)
不规范:
x = '%s%s' % (a, b) # 在这个例子中应该使用+来合并字符串
x = '{}{}'.format(a, b) # use + in this case
x = imperative + ', ' + expletive + '!'
x = 'name: ' + name + '; score: ' + str(n)
避免在循环中用+和+=操作符来累加字符串。由于字符串是不可变的, 这样做会创建不必要的临时对象, 并且导致二次方而不是线性的运行时间。作为替代方案, 你可以将每个子串加入列表, 然后在循环结束后用 .join 连接列表。(也可以将每个子串写入一个 cStringIO.StringIO 缓存中)。
规范:
items = ['<table>']
for last_name, first_name in employee_list:
items.append('<tr><td>%s, %s</td></tr>' % (last_name, first_name))
items.append('</table>')
employee_table = ''.join(items)
不规范:
employee_table = '<table>'
for last_name, first_name in employee_list:
employee_table += '<tr><td>%s, %s</td></tr>' % (last_name, first_name)
employee_table += '</table>'
在同一个文件中, 保持使用字符串引号的一致性。使用单引号’或者双引号”之一用以引用字符串, 并在同一文件中沿用. 在字符串内可以使用另外一种引号, 以避免在字符串中使用。
为多行字符串使用三重双引号”””而非三重单引号’’’。当且仅当项目中使用单引号’来引用字符串时, 才可能会使用三重’’’为非文档字符串的多行字符串来标识引用. 文档字符串必须使用三重双引号”””。不过要注意, 通常用隐式行连接更清晰, 因为多行字符串与程序其他部分的缩进方式不一致。
规范:
print ("This is much nicer.\n"
"Do it this way.\n")
不规范:
print """This is pretty ugly.
Don't do this.
"""
类¶
如果一个类不继承自其它类, 就显式的从object继承. 嵌套类也一样。继承自 object 是为了使属性(properties)正常工作, 并且这样可以保护你的代码, 使其不受Python 3000的一个特殊的潜在不兼容性影响。这样做也定义了一些特殊的方法, 这些方法实现了对象的默认语义, 包括 new, init, delattr, getattribute, setattr, hash, repr, and str 。
规范: class SampleClass(object):
pass
不规范: class SampleClass:
pass
命名规范¶
遵循Python之父Guido推荐的规范:
Ø 所谓”内部(Internal)”表示仅模块内可用, 或者, 在类内是保护或私有的.
Ø 用单下划线(_)开头表示模块变量或函数是protected的(使用import * from时不会包含).
Ø 用双下划线(__)开头的实例变量或方法表示类内私有.
Ø 将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块.
Ø 对类名使用大写字母开头的单词(如CapWords, 即Pascal风格), 但是模块名应该用小写加下划线的方式(如lower_with_under.py). 尽管已经有很多现存的模块使用类似于CapWords.py这样的命名, 但现在已经不鼓励这样做, 因为如果模块名碰巧和类名一致, 这会让人困扰。
| Type | Public | Internal |
|---|---|---|
| Modules(模块) | lower_with_under | _lower_with_under |
| Packages(包) | lower_with_under | |
| Classes(类) | CapWords | _CapWords |
| Exceptions(异常) | CapWords | |
| Functions(函数) | lower_with_under() | _lower_with_under() |
| Global/Class Constants(全局/类常量) | CAPS_WITH_UNDER | _CAPS_WITH_UNDER |
| Global/Class Variables(全局/类变量) | lower_with_under | _lower_with_under |
| Instance Variables(实例变量,即类型的成员变量,且是非静态(即非static)的) | lower_with_under | _lower_with_under (protected) or __lower_with_under (private) |
| Method Names(类方法) | lower_with_under() | _lower_with_under() (protected) or __lower_with_under() (private) |
| Function/Method (函数)Parameters(参数) | lower_with_under | |
| Local Variables(局部变量) | lower_with_under |
应该避免的名称:
Ø 单字符名称, 除了计数器和迭代器.
Ø 包/模块名中的连字符(-)
Ø 双下划线开头并结尾的名称(Python保留, 例如__init__)
对于变量的命名,有以下要求:
1)bool类型的变量,以is_开头,例如:is_running
注释规范¶
确保对模块, 函数, 方法和行内注释使用正确的风格。
块注释和行注释¶
最需要写注释的是代码中那些技巧性的部分。如果你在下次代码审查 的时候必须解释一下, 那么你应该现在就给它写注释。对于复杂的操作, 应该在其操作开始前写上若干行注释。对于不是一目了然的代码, 应在其行尾添加注释。
为了提高可读性, 注释应该至少离开代码2个空格。另一方面, 绝不要描述代码。假设阅读代码的人比你更懂Python, 他只是不知道你的代码要做什么。
# We use a weighted dictionary search to find out where i is in
# the array. We extrapolate position based on the largest num
# in the array and the array size and then do binary search to
# get the exact number.
if i & (i-1) == 0: # true iff i is a power of 2
TODO注释¶
TODO 表示需要做而未做的一些待完成的事项,有助于事后的检索,以及对整体项目做进一步的修改迭代。
格式如下:
TODO注释应该在所有开头处包含“TODO”字符串,
紧跟着是用括号括起来的你的名字, email地址或其它标识符。
然后是一个可选的冒号. 接着必须有一行注释, 解释要做什么. 主要目的是为了有一个统一的TODO格式,
这样添加注释的人就可以搜索到(并可以按需提供更多细节)。
举例:
# TODO(kl@gmail.com): Use a "*" here for string repetition.
# TODO(Zeke) Change this to use relations.
FIXME注释¶
FIXME 表示需要修复的bug,优先级比TODO高,有助于发现问题时标记记录,避免发现问题后忘记进行修复。
格式如下:
FIXME注释应该在所有开头处包含“FIXME”字符串,
紧跟着是用括号括起来的你的名字, email地址或其它标识符。
然后是一个可选的冒号. 接着必须有一行注释, 解释要做什么. 主要目的是为了有一个统一的FIXME格式,
这样添加注释的人就可以搜索到(并可以按需提供更多细节)。
举例:
# FIXME(kl@gmail.com): 这里存在被除数为0的异常情况未处理
# FIXME(Zeke) 未处理接口超时的情况
Docstring规范¶
Python的Docstring规范有多个标准,包括Google、numpy等,本规范为作者自定义的SnakerPy规范,因为平常也会开发Javascript等代码,因此在标签定义上统一参考JSDoc的规范,减少多个规范的学习成本。JSDoc的详细标签格式可参考《JSDoc中文文档》。
Python类型¶
number : Number(数字)
int : 整形
float :浮点数
bool :布尔值
complex :复数
string : String(字符串),也可以简写为 str
list : List(列表),可以与基础类型组合,例如:int[],string[]
tuple : Tuple(元组),可以与基础类型组合,例如:int(),string()
set : Set(集合),无序不重复元素的序列,可以与基础类型组合,例如:int{}
dict : Dictionary(字典),数据字典,应包括类型,例如dict[string: int],前面为key类型,后面为value类型
object :object实例
function : 函数对象,函数的入参和返回值说明应在参数描述中说明
其他具体类实例:应为类的全路径,例如package.ClassName
@typedef¶
@typedef标签在描述自定义类型时是很有用的,特别是如果你要反复引用它们的时候。这些类型可以在其它标签内使用,如 @type 和 @param。
该标签的位置应紧跟在import区之后,格式如下:
"""
<descript>
@typedef {(type1|type2)} typename - [type-descript]
"""
@typedef {(type1|type2)} typename - [type-descript] :可以用”|”将多个类型组织起来,重新定义一种新数据类型,[type-descript]可根据需要是否增加补充描述
公共选填标签¶
以下标签为所有注释都可以选填的标签:
@summary
@example : 提供一个如何使用描述项的例子,示例内容在标签下方
@deprecated [
@since
@see <namepath/text]>: 表示可以参考另一个标识符的说明文档,或者一个外部资源。您可以提供一个标识符的namepath或自由格式的文本
@tutorial
@version
@ignore : 标签表示在你的代码中的注释不应该出现在文档中,注释会被直接忽略。这个标签优先于所有其他标签
@todo
模块(Module)注释¶
注释的位置在文件头定义(例如:#!/usr/bin/python2)后面,import、模块变量及代码前面,格式如下:
"""
<descript>
@module <fullname>
@file <filename>
"""
必填标签:
descript :模块的具体描述
@module
@file
选填标签:
@license
@copyright
@requires
@author
注:模块这里并未强制指定作者等标签,原因是按照本规范作者等信息会作为模块变量放入代码中便于随时使用
类注释¶
类注释紧跟类定义后面,使用三重双引号”””引用注释字符串,格式如下:
"""
<descript>
"""
必填标签:
descript :类的具体描述
选填标签:
@abstract :标识类是抽象类,需子类重载实现相关内容
函数注释¶
注释紧跟函数定义后面,使用三重双引号”””引用注释字符串,格式如下:
"""
<descript>
@param {type} <paraname> - <descript>
@returns {type} - <descript>
@throws {exception-type} - <descript>
"""
必填标签:
@decorators
@param {type}
type :为参数的数据类型,如果允许任何类型,填入*;如果支持几种特定类型,通过竖线"|"分隔
paraname : 参数名,如果为可选参数,paraname要用中括号"[ ]"标识(例如"[filepath]");如果参数有默认值,参数名后面带默认值,例如"[filepath]='c:/'";如果参数的取值枚举值,则参数名后面带枚举标识指示,例如“my_type=enum['type1', 'type2', 'type3']”, 如果同时为枚举值并需要指定默认,则在默认选项前加*标识,例如 “my_type=enum['type1', *'type2', 'type3']”
descript : 参数描述
注:paraname 与descript 之间用 “ - ”分隔;如果描述有多行,应进行格式的缩进处理
@returns {type} -
@throws {exception-type} -
选填标签:
@api {action-type} {protocol}
@header-in {type}
@header-out {type}
@body-in {type}
@body-out {type}
@sub-body-begin {block|option|repeat} : 标识报文主体出入参的子参数块开始,用于实现参数嵌套指示;标签后通过选项指示子参数块出现的次数限制,block代表出现一次,option代表可以没有也可以出现一次,repeat代表循环出现,默认为block
@sub-body-end : 标识报文主体出入参的子参数块结束
@abstract :标识类是抽象对象,需子类重载实现相关内容
@override :指明一个标识符覆盖其父类同名的标识符
@access <private|protected|public> :指定该成员的访问级别(私有 private,公共 public,或保护 protected)
@static : 标记方法是否静态方法
@interface [@interface标签添加到父类,以指明子类必须实现父类的方法和属性
属性注释¶
注释紧跟属性定义后面,使用三重双引号”””引用注释字符串,格式如下:
"""
<descript>
@property {type}
"""
必填标签:
@property {type} :标记对象为属性,type为属性的类型
选填标签:
@static : 标记方法是否静态方法
@readonly :标记方法是只读的(只有get,没有set)
@access <private|protected|public> :指定该成员的访问级别(私有 private,公共 public,或保护 protected)
注:对于属性的注释,只要在第一个里定义就可以了,setter无需再重复注释
示例:
@property
def server_opts(self):
"""
获取/设置服务器启动参数
@property {object}
@example
//获取
opts = serverobj.server_opts
//修改
serverobj.server_opts = opts
"""
return self._server_opts
@server_opts.setter
def server_opts(self, value):
self._server_opts = value
枚举注释¶
注释紧跟枚举定义后面,使用三重双引号”””引用注释字符串,格式如下:
"""
<descript>
@enum {type}
"""
必填标签:
@enum {type} :标记对象为枚举对象,type为属性的类型
示例:
class EnumColunmType(Enum):
"""
数据字段类型
@enum {int}
"""
Int = 0 # 整型数字
Number = 1 # 数字类型(需指定精度)
Char = 2 # 定长字符串
VChar = 3 # 变长字符串
Date = 4 # 日期时间,精确到秒
TimeStamp = 5 # 时间戳,精确到毫秒
Blob = 6 # 二进制数据
CBlob = 7 # 字符类型数据
编码规范¶
字符串指定编码¶
Python 代码中,非 ascii 字符的字符串,需添加u前缀:
asc_str = "test"
utf_str = u"中国"
文件(*.py)开头¶
大部分.py文件不必以#!作为文件的开始. 根据 PEP-394,程序的main文件应该以 #!/usr/bin/python2或者 #!/usr/bin/python3开始。
本规范中要求所有.py文件都以#!开头,并按以下规范格式作为文件开头:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
注:在计算机科学中, Shebang (也称为Hashbang)是一个由井号和叹号构成的字符串行(#!), 其出现在文本文件的第一行的前两个字符。在文件中存在Shebang的情况下, 类Unix操作系统的程序载入器会分析Shebang后的内容, 将这些内容作为解释器指令, 并调用该指令, 并将载有Shebang的文件路径作为该解释器的参数。例如, 以指令#!/bin/sh开头的文件在执行时会实际调用/bin/sh程序。
#!先用于帮助内核找到Python解释器, 但是在导入模块时, 将会被忽略,因此只有被直接执行的文件中才有必要加入#!。
Main脚本执行¶
即使是一个打算被用作脚本的文件,也应该是可导入的,并且简单的导入不应该导致这个脚本的主功能(main functionality)被执行, 这是一种副作用。主功能应该放在一个main()函数中。
在Python中,pydoc以及单元测试要求模块必须是可导入的。你的代码应该在执行主程序前总是检查 if __name__ == '__main__' , 这样当模块被导入时主程序就不会被执行。if __name__ == '__main__'的执行代码应放在文件的最后。
def main():
...
if __name__ == '__main__':
main()
所有的顶级代码在模块导入时都会被执行. 要小心不要去调用函数, 创建对象, 或者执行那些不应该在使用pydoc时执行的操作。
模块信息¶
每个.py文件是Python的一个模块,模块的信息如模块名、版本、作者、开发时间等信息,由以下的模块内部变量进行定义,该部分的定义必须直接跟在import定义和@typedef之后:
__MOUDLE__ = 'EnumClass'
__DESCRIPT__ = 'PADO枚举值定义'
__VERSION__ = '0.9.0'
__AUTHOR__ = 'snaker'
__PUBLISH__ = '2017.10.28'
如果模块不涉及独立执行,而仅被第三方引用,建议增加if __name__ == '__main__'模块执行模块信息的打印,格式如下:
if __name__ == '__main__':
# 当程序自己独立运行时执行的操作
# 打印版本信息
print(('模块名:%s - %s\n'
'作者:%s\n'
'发布日期:%s\n'
'版本:%s' % (__MOUDLE__, __DESCRIPT__, __AUTHOR__, __PUBLISH__, __AUTHOR__)))
高阶编码技巧 (非规范)¶
函数入参默认值初始化¶
Python支持修改函数的入参值:对于不可变变量(int、string等每次修改都会新创建内存的对象),函数内部修改入参值不会对外部有任何影响;但对于可变变量(list、dict等),函数内部是可以修改变量值的,因此可以基于这个机制实现入参的in_out模式(通过入参输出结果)。
同时Python的函数入参支持设置默认值,但默认值的初始化机制有一个坑,即默认值的初始化是在模块加载的时候执行,并非每次调用重新初始化,因此如果多次调用函数,且对默认值的入参进行了修改,将会将值传导到下一次调用,而不是按开发人员的预期执行,例如:
def func(list=[]):
x.append(2)
print x
func()
func()
以为打印的都是[2],但实际运行结果:
[2]
[2, 2]
针对这个问题,要求函数入参默认值设置必须按以下规则处理: (1)不可变变量(int、string等)的入参默认值可以直接在定义中初始化; (2)可变变量及对象(list、dict、类实例等)的入参默认值应为None,入参的初始化在函数代码中处理。
规范:
def fun(para1=1, para2=’string’, para3=None):
if para3 is None:
para3 = list()
……
不规范:
def fun(para1=1, para2=’string’, para3=list()):
……
异常处理¶
所有的函数/方法应考虑异常情况,对于不处理异常并抛出异常的设计,应在注释的@throws中列出会产生的异常清单;对于设计为不会抛出异常的情况,应保证全部代码不会抛出异常(通过try…except模式将可能出现异常的代码包住)。
此外应遵循以下异常捕获原则:
1)尽量只包含容易出错的位置,不要把整个函数 try catch
2)对于不会出现问题的代码,就不要再用 try catch了
3)只捕获有意义,能显示处理的异常
4)能通过代码逻辑处理的部分,就不要用 try catch
5)异常忽略,一般情况下异常需要被捕获并处理,但有些情况下异常可被忽略,只需要用 log 记录即可,可参考一下代码:
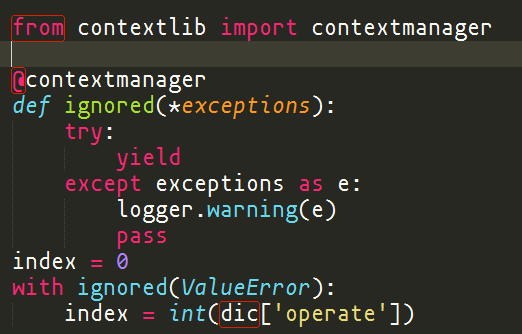
文件和sockets¶
在文件和sockets结束时, 显式的关闭它。
除文件外, sockets或其他类似文件的对象在没有必要的情况下打开, 会有许多副作用, 例如:
它们可能会消耗有限的系统资源, 如文件描述符。如果这些资源在使用后没有及时归还系统, 那么用于处理这些对象的代码会将资源消耗殆尽。
持有文件将会阻止对于文件的其他诸如移动、删除之类的操作.
仅仅是从逻辑上关闭文件和sockets, 那么它们仍然可能会被其共享的程序在无意中进行读或者写操作。只有当它们真正被关闭后, 对于它们尝试进行读或者写操作将会跑出异常, 并使得问题快速显现出来。
而且, 幻想当文件对象析构时, 文件和sockets会自动关闭, 试图将文件对象的生命周期和文件的状态绑定在一起的想法, 都是不现实的。因为有如下原因:
没有任何方法可以确保运行环境会真正的执行文件的析构。不同的Python实现采用不同的内存管理技术, 比如延时垃圾处理机制。延时垃圾处理机制可能会导致对象生命周期被任意无限制的延长。
对于文件意外的引用,会导致对于文件的持有时间超出预期(比如对于异常的跟踪, 包含有全局变量等)。
推荐使用 “with”语句以来管理文件的释放:
with open("hello.txt") as hello_file:
for line in hello_file:
print line
对于不支持使用”with”语句的类似文件的对象,推荐使用 contextlib.closing():
import contextlib
with contextlib.closing(urllib.urlopen("http://www.python.org/")) as front_page:
for line in front_page:
print line
注:with、contextlib.closing的用法,请参考:
Python的with…as的用法:https://www.cnblogs.com/itcomputer/articles/4601411.html
Python3 之 contextlib:https://www.cnblogs.com/wang-yc/p/6640873.html
with…as的用法¶
在编码时如果需要在某代码块结束的时候执行指定的工作(如释放资源,关闭文件等),通常会使用传统的try…finally语法,但在Python代码中有可读性更好的with语法可替代try…finally语法(注意:前提是对象支持with):
with EXPRESSION [ as VARIABLE] WITH-BLOCK
对于自定义的类,建议遵循with语法的规范让类支持with语法使用方式,以便在类对象的使用中应用可读性更高的with语法。
with语法规范要求如下:
基本思想是with所求值的对象必须有一个
__enter__()方法,一个__exit__()方法;with语句后面的表达式(EXPRESSION)执行后,所返回对象的
__enter__()方法将被调用,并将__enter__()方法的返回值赋值给as后面的变量;with后面的代码块全部被执行完之后,将将调用前面返回对象的
__exit__()方法。
Python的文件类直接支持with语法,举例如下:
传统try…finally代码写法:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
替换为with的代码写法:
with open("/tmp/foo.txt") as file:
data = file.read()
自定义类支持with的举例如下:
#!/usr/bin/env python
# with_example01.py
class Sample:
def __enter__(self):
print "In __enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In __exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
执行结果为:
In __enter__()
sample: Foo
In __exit__()
语句的执行顺序说明如下:
1) __enter__()方法被执行
2)__enter__()方法返回的值 - 这个例子中是”Foo”,赋值给变量’sample’
3)执行代码块,打印变量”sample”的值为 “Foo”
4)__exit__()方法被调用with真正强大之处是它可以处理异常。可能你已经注意到Sample类的__exit__方法有三个参数- val, type 和 trace。这些参数在异常处理中相当有用。
上面的例子是通过外部函数返回支持with的对象,以下例子是直接在类中支持with使用:
class Query(object):
def __init__(self, name):
self.name = name
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def query(self):
print('Query info about %s...' % self.name)
使用方式如下:
with Query('Bob') as q:
q.query()
使用contextlib支持with¶
使用with规范编写 enter 和 exit 仍然很繁琐,因此Python的标准库 contextlib 提供了更简单的写法,让我们能用更简便的方式来支持with语法。
第一种方式是利用@contextmanager修饰符以及yield语法,示例如下:
from contextlib import contextmanager
class Query(object):
def __init__(self, name):
self.name = name
def query(self):
print('Query info about %s...' % self.name)
@contextmanager
def create_query(name):
print('Begin')
q = Query(name)
yield q
print('End')
@contextmanager 这个装饰器接受一个 generator,用 yield 语句把 with … as var 把变量输出出去,然后,with 语句就可以正常的工作了: parana
with create_query('Bob') as q:
q.query()
下面的例子是通过@contextmanager方式在某段代码执行前后自动执行特定代码:
@contextmanager
def tag(name):
print("<%s>" % name)
yield
print("</%s>" % name)
with tag("h1"):
print("hello")
print("world")
执行结果:
<h1>
hello
world
</h1>
代码的执行顺序是:
1) with 语句 首先执行 yield 之前的语句,因此打印出
.
2)yield 调用会执行 with 语句内部的所有语句,因此打印出 hello 和 world.
3)最后执行yield之后的语句,打印出 .
第二种方式更为简便,利用closing()没有实现上下文的对象支持with语句,但要求返回的对象实现close ()方法示例如下:
from contextlib import closing
from urllib.request import urlopen
with closing(urlopen('https://www.python.org')) as page:
for line in page:
print(line)
另外一个更直观的例子:
from contextlib import closing
class Door(object) :
def open(self) :
print 'Door is opened'
def close(self) :
print 'Door is closed'
with closing(Door()) as door :
door.open()
实际上closing()也是利用@contextmanager修饰符,实现原理如下:
@contextmanager
def closing(thing):
try:
yield thing
finally:
thing.close()
灵活使用yield降低内存消耗¶
对于有些业务逻辑,需要将批量生成数据并放入list中,然后循环对list的对象进行处理。由于list对象一旦生成就全部数据存入内存,如果批量数据量比较大,将导致内存消耗过大。对这类情况建议通过生成器(generator)将数据处理成迭代对象(iterable),不将所有数据一次性存入内存,而是由迭代对象的next函数逐条取数据并进行处理。 例如需要通过fab函数生成指定大小的list,然后进行打印: 全量生成list,占用内存较大:
def fab(max):
n, a, b = 0, 0, 1
L = []
while n < max:
L.append(b)
a, b = b, a + b
n = n + 1
return L
for n in fab(5):
print n
修改为迭代对象(iterable)模式,每次循环才生成数据,不占用内存,但相对复杂:
class Fab(object):
def __init__(self, max):
self.max = max
self.n, self.a, self.b = 0, 0, 1
def __iter__(self):
return self
def next(self):
if self.n < self.max:
r = self.b
self.a, self.b = self.b, self.a + self.b
self.n = self.n + 1
return r
raise StopIteration()
for n in Fab(5):
print n
使用yield实现迭代,实现上更简洁和直观:
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b
# print b
a, b = b, a + b
n = n + 1
for n in fab(5):
print n
以下说明一下yield的原理,让大家在使用的时候更明确会出现什么效果:
(1)yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行;
(2)简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始;
(3)使用了yield的函数与一般的迭代对象一样,具有next()(python3中为__next__())方法和send(msg)(python3中为__send__(msg))方法;
(4)next()方法返回当前迭代遇到yield时,yield后面表达式的值;
(5)在一个 generator function 中,如果没有 return,则默认执行至函数完毕,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。
以下为展示原理的示例:
def yield_test(n):
for i in range(n): # range返回整数列表,从0开始,步长为1
yield call(i)
print("i=",i)
#做一些其它的事情
print("do something.")
print("end.")
def call(i):
return i*2
#使用for循环
for i in yield_test(5):
print(i,",")
输出结果是:
> > > 0 ,
> > > i= 0
> > > 2 ,
> > > i= 1
> > > 4 ,
> > > i= 2
> > > 6 ,
> > > i= 3
> > > 8 ,
> > > i= 4
> > > do something.
> > > end.
使用next的调用方法:
f = yield_test(10)
while True:
try:
print(f.__next__())
except:
break;